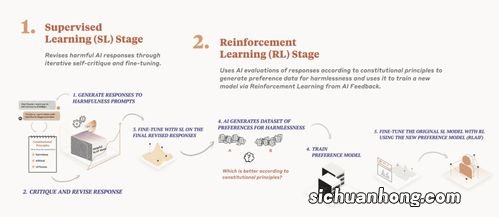
在LLM对偏好进行标注后,将训练嘉奖模型(RM)来预测偏好 。由于研究人员的方法产生软标注(Soft Label) , 他们采取RM生成的嘉奖分数的softmax的交叉熵损失(cross-entropy loss) , 而不是嘉奖模型中提到的损失 。
文章插图
Softmax将RM的无界分数(unbounded scores)转换为几率散布 。
在AI标注数据集上训练RM可以被视为模型蒸馏的一种情势,特别是由于研究人员的AI标注器通常比RM更大、更强 。
另外一种方法是绕过RM并直接使用AI反馈作为RL中的嘉奖信号,虽然这类方法的计算成本更高,由于AI标注器比RM更大 。
通过经过训练的RM,研究人员使用适用于语言建模领域的Advantage Actor Critic (A2C)算法的修改版本进行强化学习 。
【AI反馈的强化学习】关于本次AI反馈的强化学习的问题分享到这里就结束了,如果解决了您的问题 , 我们非常高兴 。
猜你喜欢
- 简单的数学计算测试
- 人工智能的机遇和安全论
- Github Copilot:最好的AI代码助手
- 选择合适你目标和兴趣的编程语言
- 智能感知 2.0
- 可履行的人工智能教育才有未来
- 网贷中介依附在借款人身上,为犯法网贷机构输送利润
- 下一个10年,中国将迎来物联网时代
- 打工不可能打工,一生不可能打工