
通过机器快捷判定舆情事件的初步情况,能够为人的综合判断和设计应对方案提供一个好的路线图,以便于舆情苗头出现之际快速发现信号、舆情发酵过程中检验应对有效性,以及在后期科学评判处置效果 。
情感分析又被称为情感倾向性分析或意见挖掘,是从用户意见中提取信息的过程 。文本情感分析则致力于将单词、句子、段落和篇章映射到一组相对应的情感类别上,继而得到一个可用于划分情感状态的心理学模型 。
文本情感分析是舆情事件研判过程中的关键一步 。当我们基于机器现成的舆情事件情感占比结果,研判舆情态势、针对性的采取相应策略时,也需要停下来想一想,舆情情感被测量的背后机理是什么?
总体而言,文本情感分析通常要经过以下几个过程:一是文本清洗 。筛除与文本无关的噪声数据 。二是对文本进行分词处理 。目的是将文本分为单独的词,然后转换为词向量,也就是将自然语言转化为机器语言,随即使用模型处理数据 。三是获取特征 。从这一步开始有四种不同的方法,分别是基于情感词典与规则的方法、传统机器学习方法、深度学习方法、多策略混合方法 。四是使用模型分类 。利用四种方法特有的模型对词、句、篇章蕴含的情感进行分析和预测其类别 。五是根据预测结果 , 把文本分到相应的类别中 。
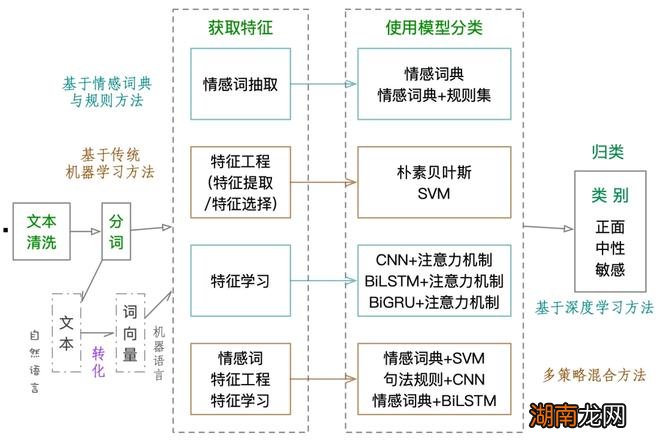
在文本清洗阶段,首先对文本数据进行去停用词、去除换行符等清洗工作 , 统一英文数据、集中英文字母的大小写,并将数据序列化 。这个过程由专门的成熟工具完成 。
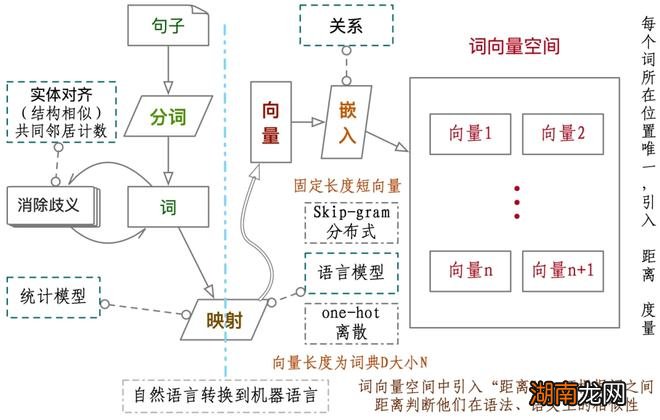
由于计算机不能够直接理解人类的自然语言,对自然语言进行建模是让计算机能够运用自然语言进行计算的第一步 。在自然语言处理任务中 , 首先需要考虑词如何在计算机中表示 。研究自然语言的时候,都是需要把大量文本划分为最小知识单元,也就是把文章、段落、句子都划分为词 。
【爱情类型名人百科网站】分词算法的原理是基于词典进行扫描,生成有向无环图;然后是根据词频进行最大化的切分与组合;最后使用基于汉字成词能力的HMM模型提取新词(该模型主要使用了Viterbi算法)完成对中文文本的词法分析 。精确模式、全模式和搜索引擎模式是三种分词模式 。精确模式就是将词最准确的划分出来,没有多余的词,这种分词方法最适用于对文本进行一些分析操作 。分词原理及过程见下图 。
基于情感词典与规则的方法获取特征,需要抽取出情感词,即从文本中自动识别出情感词来 。如基于有限状态机(FiniteStateMachine,FSM)的匹配方法名人百科网站 。情感元素抽取过程分三个步骤 。第一步,情感元素匹配,主要是将经过预处理的评论语料映射到特征词和否定副词的列表中,这些列表根据在元素评论中出现的顺序进行排序 。第二步,情感元素抽取,将列表数据作为FSM的输入 , 根据上下文和情感词寻找特征意见(Feature-Opinion,F-O)对,并确定每对F-O对的情感极性 。第三步 , 情感元素过滤,利用规则筛选出正确的F-O对 。
机器学习中提升效率和获得更好结果高度依赖于数据预处理爱情类型,同时整个学习过程70%工作量也在此 , 数据预处理包括清洗、转换、规约三个部分,其中的规约是一个降维过程 , 在机器学习中通过特征工程实现 。特征工程包括特征提取和特征选择两类,前者是保留所有特征但区别对待 , 如因子分析;后者是只留下最有效的特征,如矩阵的奇异值分解、Filter、Wrapper、Embedded等 。是一个人工 机器共同实现的方法名人百科网站 。
特征学习是深度学习中的用语,与机器学习中用于降维的特征工程不一样 , 是主动寻找隐藏特征,深度学习由多层网络构成,每一层学习一个特征 。如CNN中通过卷积运算和池化方法构成的一层人工神经元集合中 , 通过前馈方法就能学习出图像、语言、文本的一个特征 。基于深度学习方法获得特征都是完全自动实现的 。
基于情感词典与规则的方法 。该方法主要依赖于情感词典的构建,是指利用情感词典获取文档中情感词的情感值爱情类型 , 再通过加权计算确定文档的整体情感倾向 。使用此方法时不考虑词语之间的联系,词语的情感值不会随着应用领域和上下文的变化而变化,因此需要针对特定领域建立相关的情感词典提高分类的准确率 。情感词典是情感分析系统的基础知识库名人百科网站,是数字、文本与符号的集合 。在缺乏大量训练数据集的情况下,基于词典与规则的方法相对能取得较好的分类结果且易于理解,但是网络用语不断涌现,情感词典需要不断更新扩展以提高分类的准确率 。
基于机器学习的方法,是以带有情感标签的数据训练出一个情感分类器,再利用分类器预测测试集中文本的情感倾向,常用的浅层机器学习分类算法有最大熵、朴素贝叶斯和支持向量机(SVM)等 。
与情感词典的方法相比,机器学习方法更简单,能取得更高的分类准确度 , 但是机器学习是一个监督学习方法,需要对数据集进行三类情感的类别标注 。大规模高质量的数据标注耗费极高的人工成本,人为主观的数据标注结果准确和一致性也不易保证,而模型参数的训练完全依赖数据集类标的准确性 , 因此成本压力和大量数据过载情况下都会影响其可靠和可实现性名人百科网站 。
基于深度学习的方法 。深度学习DL(DeepLearning)是指通过多层神经网络拟合训练样本分布的一种机器学习方法,它缓解了传统神经网络算法在训练多层神经网络时出现的局部最优问题,且其训练过程不依赖于样本标签信息 。
在情感分析的深度学习方法中 , 常常看到注意力机制,如CNN 注意力机制等 。注意力机制是一种类似人脑的注意力分配机制,它对重要的区域投入更多的资源,以获取更多的细节,对无用的信息则进行抑制,AI领域的从业者把这种机制引入到一些模型里,并取得了成功 。
与基于情感词典与机器学习的方法相比 , 深度学习有更强的表达能力和模型泛化能力,但是缺乏大规模的训练数据也是深度学习在情感分类中遇到的问题 。
多策略混合的方法,相较于单一模型 , 将领域新词或构建的主题情感词典与机器学习、深度学习模型相结合,可以提高情感倾向性分析的准确率 。多策略混合的方法一般分析问题更为全面和深入,具有一定优势,但是多策略混合方法的模型复杂度与训练难度更高 , 比单一模型更难以实现 。
现阶段,舆情事件不同情感分布主要分为三种情形,分别有不同的处理方法 。一是敏感跟帖所占比重很高,说明负面观点比较多,涉事主体需尽快采取处置措施避免事态扩大 。二是正面跟帖比重高 , 则可以设法延长舆情周期 , 提升宣传效果 。三是中性跟帖比较多,涉事主体则需考虑在巩固中性情感底盘的同时,如何进一步“提正抑负” 。对于以上三种状态提出了基本的应对策略 。但是实际舆情应对工作中,处理起来更为复杂名人百科网站 。
通过机器快捷判定舆情事件的初步情况 , 能够为人的综合判断和设计应对方案提供一个好的路线图,以便于舆情苗头出现之际快速发现信号、舆情发酵过程中检验应对有效性,以及在后期科学评判处置效果 。事实上 , 机器帮我们做一个先期的关于舆情事件中公众敏感、中性、和正面三种情感的分布和时间上的发展趋势,而涉事主体或者政府部门该如何处置,还是需要专业人员提供个性化的度、多因素基于现状、资源约束条件下对结果预期的最优条件下采取的策略组合,这是充分发挥人的能动性和实现应对有效性的重要路径 。因此,技术手段结合人类智力是舆情及时发现、有效处置、声誉修复的重要方法 。
[2]钟佳娃,刘巍,王思丽,杨恒.文本情感分析方法及应用综述[J].数据分析与知识发现,2021,5(06):1-13.
[6]周晓兰,戴香平,陈洪龙.基于朴素贝叶斯模型的评论文本情感分析[J].科学技术创新,2021(33):88-90.
从“阅读宠儿”到“泡面神器”,Kindle为何掉了队? 周末谈数字主持人小漾元旦亮相《你好,星期六》;北京广电全面叫停偶像养成类网综和“耽改”网剧 传媒动态【1.1-1.8】
猜你喜欢
- 男女表达情感的不同名人百科网
- 历史上李清照和赵明诚的爱情有多动人?
- 情感类型有哪些情感博主有哪些
- 恋爱情感如何回答
- 恋爱挽回情感咨询恋爱情节文案
- 大学生情感心理学名人百科网站
- 恋爱情感公司关于情感的词
- 对爱情的理解和感悟双相情感障碍自测表
- 恋爱情感语录与感悟
- 情感剥离现象性学与爱情心理学